内容详情 您现在的位置是: 首页> 其他随笔
布隆过滤器简述及应用
发布时间:2021-03-29 18:51 已围观:2189
摘要布隆过滤器简述及应用
一、布隆过滤器
1、维基百科
布隆过滤器(Bloom Filter)是1970年由布隆提出的。
实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
优点是不需要存储 key,节省空间,空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
2、原理概念
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、散列表(哈希表)等等数据结构都是这种思路,但是随着集合中元素的增加,需要的存储空间越来越大;同时检索速度也越来越慢,检索时间复杂度分别是O(n)、O(log n)、O(1)。
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
3、自我理解
直观的说,Bloom 算法类似于一个 HashSet(通过哈希算法得出元素的哈希地址,通过对比哈希地址就可以确定两个对象是否为同一个地址),用来判断某个元素(key)是否在某个集合中。
和一般的 HashSet 不同的是,Bloom Filter 算法无需存储 key 的值,对于每个 key,只需要 k 个比特位,每个存储一个标志,用来判断 key 是否在集合中。
二、算法解析
1、BloomFilter 流程
1. 首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
2. 初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
3. 某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
4. 判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
2、关于哈希冲突
假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们都在说谎,不过直觉上判断这种事情的概率是比较低的。--- 如上 BloomFilter 流程
一个 Bloom Filter 是基于一个 m 位的位向量(b1,…bm),这些位向量的初始值为0。另外,还有一系列的hash函数(h1,…,hk),这些 hash 函数的值域属于1~m。
3、算法实现示意图
一个 bloom filter 插入 {x, y, z},并判断某个值 w 是否在该数据集:
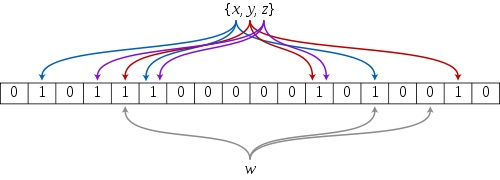
解析:m=18,k=3;插入 x 是,三个 hash 函数分别得到蓝线对应的三个值,并将对应的位向量改为1,插入 y,z 时,类似的,分别将红线,紫线对应的位向量改为1。查找时,当查找 x 时,三个 hash 值对应的位向量都为1,因此判断 x 在此数据集中。y,z 也是如此。但是查找 w 时,w 有个 hash 值对应的位向量为0,因此可以判断不在此集合中。但是,假如 w 的最后那个 hash 值是1,这时就会认为 w 在此集合中,而事实上,w 可能不在此集合中,因此可能出现误报。显然的,插入数据越多,1的位数越多,误报的概率越大。
Wiki的Bloom Filter词条有关于误报的概率的详细分析:Probability of false positives。从分析可以看出,当 k 比较大时,误报概率还是比较小的。
三、BloomFilter 的应用
1、一些应用场景
黑名单:比如邮件黑名单过滤器,判断邮件地址是否在黑名单中。
排序(仅限于 BitSet) 。
网络爬虫:判断某个URL是否已经被爬取过。
K-V系统快速判断某个key是否存在:典型的例子有 Hbase,Hbase 的每个 Region 中都包含一个 BloomFilter,用于在查询时快速判断某个 key 在该 region 中是否存在,如果不存在,直接返回,节省掉后续的查询。
2、一致性校验(ConsistencyCheck)
Background:Database migration(SQL Server migrate to MySQL),迁移后的数据一致性校验。
Design:使用 BloomFilter 进行 ConsistencyCheck
Process:
① Migrate
② Hash the MySQL tables to BloomFilter
③ Use the SQL Server tables data to check
3、Python Code:
1 import pymysql 2 import pymssql 3 import time 4 from bloompy import ScalableBloomFilter 5 6 def timenow(): 7 timestr = time.localtime(int(time.time())) 8 now = time.strftime("%Y-%m-%d %H:%M:%S", timestr) 9 return now
10 11 #configure sql server connect12 def mssql_conn():
13 conn = pymssql.connect(14 server="***",
15 user="***",
16 password="***",
17 database="***")18 return conn
19 20 #configure mysql connect21 def mysql_conn():
22 conn = pymysql.connect(23 host="***",24 port=3306,25 user="***",
26 password="***",
27 database="***")28 return conn
29 30 def bloomf():31 bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
32 conn = mysql_conn()
33 cur = conn.cursor()
34 print('*** Target table data add to BloomFilter ***n...')35 try:36 cur.execute(t_sql)37 result = cur.fetchone()38 while result != None:39 bloom.add(result)40 result = cur.fetchone()41 except:42 print ("Error: unable to fetch data.")
43 finally:44 print('Finished add.n')45 cur.close()
46 conn.close()
47 48 print(timenow(),'n*** Compare source to target data ***n...')
49 conn = mssql_conn()
50 cur = conn.cursor()
51 try:52 cur.execute(s_sql)53 num = 054 result = cur.fetchone()55 while result != None:
56 if result in bloom:57 pass58 else:59 print('{} is not in the bloom filter,not in Target table {}.'.format(result,tab))60 num += 161 result = cur.fetchone()62 if num == 0:63 64 print('Result: {} ==> Target table data matches source table data.'.format(tab))65 else:66 print('nResult: Need to compare output to repair data.')67 except:68 print ("Error: unable to fetch data.")69 finally:70 cur.close()
71 conn.close()
72 73 74 if __name__ == '__main__':
75 tab ='***'76 t_sql='select concat(***, ***, ***, UpdateDate) from ***;'77 s_sql="select convert(varchar(20),***)+convert(varchar(20),***)+convert(varchar(20),***,20)+convert(varchar(25),UpdateDate,21)+'000' from ***"78 print('#Start:',timenow(),'n')79 bloomf()80 print('n#End:',timenow())
@author:http://www.cnblogs.com/geaozhang/
声明:本文内容摘自网络,版权归原作者所有。如有侵权,请联系处理,谢谢~
转发:GeaoZhang--https://www.cnblogs.com/geaozhang/p/11373241.html
赞一个 (413)
上一篇: 理解代价函数
下一篇: Pandas 库之 DataFrame








